短纤维增强复合材料(SFRC)因其适用于注塑成型且性能优于未填充聚合物而日益受到青睐。了解其性能对于预测潜在损伤和优化其在各种应用中的使用至关重要。.
为了模拟钢纤维增强混凝土(SFRC),我们探索了微观力学方法,重点关注平均场模型和全场模型。平均场模型虽然计算效率高,但缺乏细节信息。全场方法虽然精度高,但耗时较长,且需要大量的计算资源。.
在本篇博客中,我们将介绍使用神经网络进行短纤维复合材料建模相对于传统方法的优势。我们将涵盖隐藏层、激活函数、训练、验证、归一化和评估等关键方面。阅读完本文后,您将了解如何设计和实现用于精确建模短纤维复合材料的神经网络,并了解使用这些先进技术的优势和流程。.
Short Fiber Composite and Micro-Mechanical Modeling Approaches
短纤维增强复合材料(SFRC)因其适用于注塑成型工艺且性能优于未填充聚合物,在各种应用领域中日益普及。因此,对这些短纤维复合材料的性能进行建模以预测潜在损伤至关重要。.
为了以一般方式模拟短纤维复合材料的行为,微观力学建模方法。这些模型通常可以分为两大类:平均场模型和全场模型。.
平均场模型考虑了微观结构组分内的平均应力和应变,因此计算效率很高。然而,这些模型无法提供微观结构层面的变形机制或不同相之间相互作用的详细信息。此外,它们的精度也低于全场模型。.
传统的全场方法利用详细而全面的模拟来精确地表征材料或系统在整个目标区域内的行为。这些方法通常需要通过反复试验来创建合适的代表性体积单元(RVE)。这种方法计算量大且耗时,因为它需要模拟材料在不同条件下的行为以确保精度。此外,传统的全场方法还需要消耗大量的内存和计算能力来维护和分析精确建模所需的大量数据。.

This package introduces a micromechanical approach to modeling short fiber composite damage using mean-field homogenization (MFH). It teaches how to implement this technique in Abaqus via a UMAT subroutine, offering a simplified method for analyzing the material’s stiffness and strength based on fiber and matrix properties.
A micromechanics-based artificial neural network
输入参数:神经网络使用方向张量和体积分数作为输入,从而无需反复试验即可生成合适的 RVE 实现,从而实现具有所需属性和全场精度的建模。.
内存和计算时间:神经网络使用权重和偏差来存储学习到的知识,从而显著减少所需的内存和计算时间。.
迁移学习:神经网络可以利用迁移学习来增强模型。例如,神经网络可以从原始网络继承归一化和可训练参数,并使用新的数据集进行微调,从而在数据量较少的情况下提高准确率。.
处理未见过的情况:先用较大的数据集进行训练,然后用较小的数据集进行微调,这种微调后的神经网络能够以高度准确的预测来处理未见过的负载情况。.
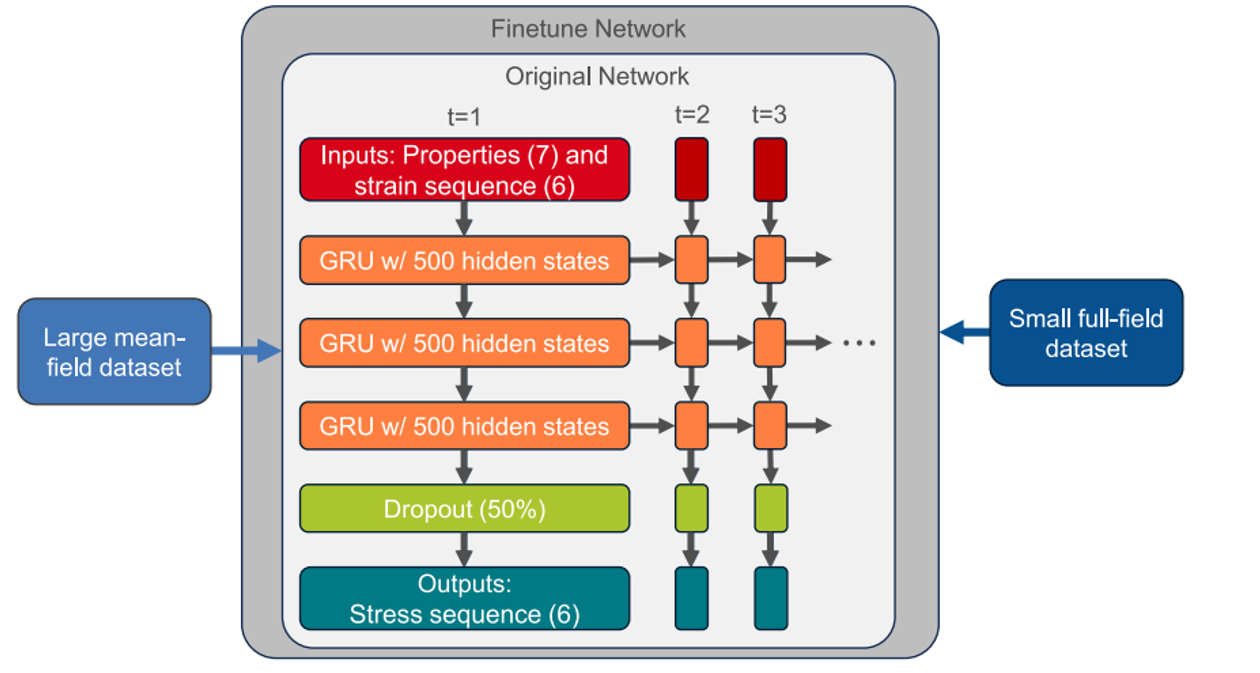
图 1:网络架构以及利用大型平均场数据集和小型全场数据集的迁移学习方法
How the neural network is modeled?
在神经网络建模中,关键要素包括隐藏层、激活函数、训练、验证、归一化和评估。密集隐藏层通过跨层神经元的完全连接,使网络能够逼近复杂的函数。指数线性单元(ELU)激活函数引入了非线性,增强了网络学习复杂模式的能力。训练过程涉及迭代调整权重以最小化损失,而验证则评估模型在未见过的数据上的性能,以检测过拟合。将输入数据归一化到公共范围(通常为 [0, 1])有助于提高学习效率并加快训练速度。 Abaqus收敛性. 评估采用平均相对误差 (MeRE) 和最大相对误差 (MaRE) 等指标来全面评估模型性能,确保神经网络稳健、准确,并能熟练处理复杂的数据模式。.
在构建神经网络模型时,隐藏层、激活函数、训练、验证、归一化和评估等关键组件至关重要。隐藏层,特别是全连接层,通过将每一层中的每个神经元与前一层中的每个神经元连接起来,使神经网络能够逼近复杂的数学函数。指数线性单元(ELU)激活函数引入了非线性,增强了网络学习复杂模式的能力。.
训练过程涉及在多个迭代周期内调整权重以最小化损失函数,而验证过程则评估模型在未见过的数据上的泛化能力,有助于检测过拟合。将输入数据归一化到公共范围(通常为 [0, 1])可以确保高效学习和更快的收敛速度。最后,评估过程使用平均相对误差 (MeRE) 和最大相对误差 (MaRE) 等指标来全面评估模型的性能。这种整体方法确保神经网络具有鲁棒性、准确性,并且能够处理复杂的数据模式。.
现在,让我们详细解释一下每一个细节。.
Design of Hidden Layers
神经网络的隐藏层可以逼近任何数学函数。本研究仅使用全连接层。在全连接层中,每一层中的每个神经元都与前一层中的所有神经元相连。在神经网络隐藏层的设计中,全连接层是常见且基本的组成部分。全连接层,也称为全连接层,是指每一层中的每个神经元都与前一层中的每个神经元相连的层。这意味着神经元的值 ![]() 一层中的神经元与所有神经元相连
一层中的神经元与所有神经元相连 ![]() 前一层。.
前一层。.
计算 ![]() 使用激活函数执行
使用激活函数执行 ![]() 负重
负重 ![]() 以及偏见
以及偏见 ![]() 具体如下:
具体如下:
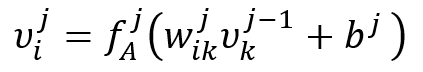
在这种设置下:
![]() 是当前层神经元的值。.
是当前层神经元的值。.
![]() 是上一层神经元的值。.
是上一层神经元的值。.
![]() 是与神经元之间连接相关的权重。.
是与神经元之间连接相关的权重。.
![]() 是神经元的偏好。.
是神经元的偏好。.
![]() 是将激活函数应用于输入加权和加上偏置项。.
是将激活函数应用于输入加权和加上偏置项。.
密集层用于逼近任何数学函数,对于神经网络学习数据中复杂模式的能力至关重要。它们在输入和输出数据之间的关系错综复杂,需要高度连接才能有效捕捉的情况下尤其有用。.
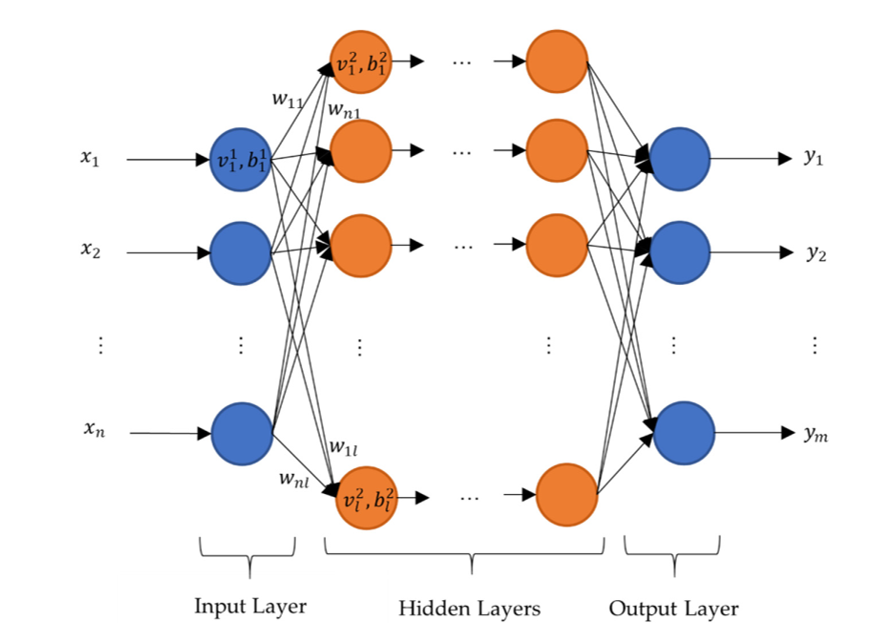
图2:具有密集层的神经网络示意图
An activation function
神经网络中的激活函数是一个应用于神经元输出的数学函数。它决定神经元是否应该被激活,本质上是判断神经元输入到网络的信号是否与预测过程相关。激活函数为网络引入非线性,使其能够学习和建模复杂的数据模式。以下是基于所提供代码片段总结的关于激活函数的一些要点:
Elu(指数线性单位):
指数线性单元(ELU)是一种用于神经网络的激活函数,它引入非线性,帮助网络学习数据中的复杂模式。ELU激活函数定义如下:
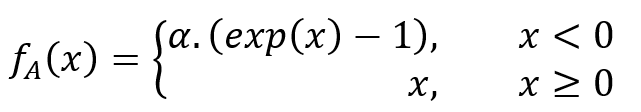
这里 a 表示标量,x 表示神经元的输入。. ![]() 这是一个标量,用于确定 ELU 函数在负网络输入时饱和的值。它是一个可调的超参数。在代码片段中描述的工作中,所有隐藏层都使用了 ELU 函数。与其他激活函数(例如 ReLU)相比,ELU 函数在训练过程中可以实现更快的收敛速度。.
这是一个标量,用于确定 ELU 函数在负网络输入时饱和的值。它是一个可调的超参数。在代码片段中描述的工作中,所有隐藏层都使用了 ELU 函数。与其他激活函数(例如 ReLU)相比,ELU 函数在训练过程中可以实现更快的收敛速度。.
Training and Validation
训练和验证是神经网络开发和评估的关键步骤。训练是指神经网络从数据中学习的过程。在训练过程中:
- 数据划分:数据集分为两部分:训练数据和验证数据。在上述研究中,数据按四分之三用于训练,四分之一用于验证的比例划分。.
- 权重调整:神经网络根据训练数据调整其权重,以最小化损失函数,损失函数衡量预测值与实际值之间的差异。.
- 训练周期:训练过程需要经过多个周期,其中一个周期是对整个训练数据集进行一次完整的遍历。.
- 损失评估:计算训练数据的损失(或误差),以监控网络的学习效果。.
验证是指评估神经网络在训练过程中未见过的独立数据集上的性能。这有助于评估模型对新数据(即未见过的数据)的泛化能力。验证过程中:
- 数据拆分:如前所述,一部分数据被留作验证数据。.
- 不进行权重调整:神经网络的权重不会根据验证数据进行调整。相反,验证数据用于评估模型的性能。.
- 验证损失:计算验证损失是为了评估网络在未见过的数据上的表现,这有助于检测过拟合。.
- 过拟合检测:当神经网络在训练数据上表现良好,但在验证数据上表现不佳时,就会发生过拟合。通过比较训练损失和验证损失,可以检测和控制过拟合。.
Normalization
归一化是机器学习和神经网络中的一个预处理步骤,它将输入数据缩放到特定范围,通常为 [0, 1] 或 [-1, 1]。此过程确保所有输入特征对学习过程的贡献相同,并有助于提高模型的收敛速度和性能。归一化确保数据的不同条目(例如刚度张量)得到同等对待。如果没有归一化,范围较大的特征可能会主导学习过程,导致训练偏差。通过将数据缩放到公共范围,用于训练神经网络的优化算法可以更快、更高效地收敛。归一化有助于避免由于输入数据的巨大差异而导致的数值不稳定问题。.
归一化通常涉及将数据缩放到特定范围。输出结果被归一化到区间 [0, 1]。归一化公式为:
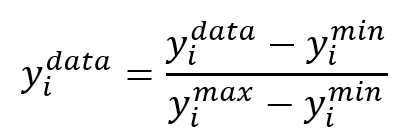
在哪里: ![]() 是数据点的归一化值。.
是数据点的归一化值。. ![]() 是数据集中数据点的最小值。.
是数据集中数据点的最小值。. ![]() 是数据集中数据点的最大值。通过对数据进行归一化,神经网络可以更有效地学习并产生更好的结果。.
是数据集中数据点的最大值。通过对数据进行归一化,神经网络可以更有效地学习并产生更好的结果。.
Evaluation
在神经网络领域,评估是指评价模型的性能,以确保其满足预期标准。以下是根据所提供信息总结的一些要点:
损失函数:在训练过程中,损失函数用于评估网络的性能。然而,由于缺乏归一化,它可能并不适合评估不同测试样本上的性能。.
替代指标:为了弥补损失函数的不足,可以使用等效冯·米塞斯应力等替代指标。该指标有助于确定平均相对误差 (MeRE) 和最大相对误差 (MaRE),从而更有效地评估神经网络的性能。评估过程确保神经网络不仅在训练数据上表现良好,而且在新数据上也同样如此。.
Use neural networks for short fiber composite model
利用神经网络构建短纤维复合材料模型时,首先要定义复合材料的结构,包括材料选择、体积分数确定、几何形状定义、材料属性定义、边界条件定义以及载荷场景定义。选择复合材料的纤维和基体材料,并计算纤维体积分数以确保性能预测的准确性。对纤维取向及其概率分布进行建模,以精确表征复合材料结构的复杂性。.
为了捕捉输入参数和输出属性之间错综复杂的关系,神经网络中的隐藏层发挥着至关重要的作用。在预训练阶段,网络会接触大量的数据集,从而学习通用模式和特征。随后,利用来自有限元方法 (FEM) 模拟或实验结果的高保真数据进行微调,以提高模型精度。这一过程确保了网络的稳健性能,使其能够有效地预测力学性能。评估阶段使用平均相对误差 (MeRE) 和最大相对误差 (MaRE) 等指标,将神经网络的预测结果与实际复合材料性能进行比较,从而突出预训练和微调的优势。 综合分析.

Modeling the Composite Structure
对于每种短纤维复合材料几何结构,将按以下顺序进行:
材料选择:
纤维和基体选择:选择复合材料中将使用的纤维类型(例如,玻璃纤维、碳纤维、芳纶纤维)和基体材料(例如,环氧树脂、聚酯树脂)。.
体积分数:
确定纤维和基体的体积分数。该比例会影响复合材料的整体性能。纤维体积分数 (φ) 是衡量复合材料中纤维含量占复合材料总体积比例的指标。.
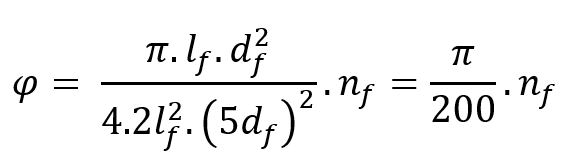
在哪里 ![]() 和
和 ![]() 分别表示纤维的长度和直径。
分别表示纤维的长度和直径。 ![]() 是一个正整数,表示RVE内部的纤维数量。使用这种方法确定RVE尺寸时,由于它依赖于离散的纤维数量场,因此无法获得连续的纤维体积分数场。因此,引入一个比例因子a进行修正:
是一个正整数,表示RVE内部的纤维数量。使用这种方法确定RVE尺寸时,由于它依赖于离散的纤维数量场,因此无法获得连续的纤维体积分数场。因此,引入一个比例因子a进行修正: ![]() ,
, ![]() . 。 最后,,
. 。 最后,, ![]() 变得依赖于
变得依赖于 ![]() , 从而可以获取纤维体积分数的连续值。.
, 从而可以获取纤维体积分数的连续值。.
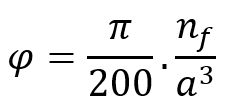
为保持最小RVE尺寸,缩放因子应大于或等于1。 ![]() . 通过增大缩放因子(从 1 开始),对于特定数量的纤维,可以获得不同的纤维体积分数。为了避免过大缩放因子,从而导致代表性体积单元 (RVE) 过大和计算成本过高,针对不同的纤维体积分数范围,选择不同数量的纤维及其对应的缩放因子。.
. 通过增大缩放因子(从 1 开始),对于特定数量的纤维,可以获得不同的纤维体积分数。为了避免过大缩放因子,从而导致代表性体积单元 (RVE) 过大和计算成本过高,针对不同的纤维体积分数范围,选择不同数量的纤维及其对应的缩放因子。.
几何定义:
形状和尺寸:定义复合材料结构的整体形状和尺寸。它可以是板、梁、壳或任何其他结构形式。对于短纤维,纤维取向非常重要。纤维取向用单位向量表示。 ![]() , 这可以用两个角度来描述
, 这可以用两个角度来描述 ![]() 和
和 ![]() . 方向向量
. 方向向量 ![]() 用笛卡尔坐标系表示为:
用笛卡尔坐标系表示为:
![]()
为了描述材料某一点的纤维取向分布,需要一个概率分布函数 p。利用取向分布和概率分布函数,可以定义一个二阶张量来描述取向分布。该张量的分量由下式给出:
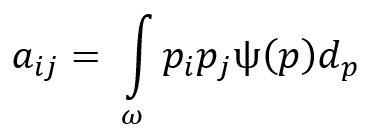
通过为不同情况创建对角方向张量来生成方向分布:在三维随机分布中 ![]() ,平面随机分布
,平面随机分布 ![]() .
.
材料特性:
弹性特性:为每一层指定弹性特性,包括:杨氏模量(E):衡量纤维方向刚度的指标(![]() )和横向(
)和横向(![]() 剪切模量 (G):衡量材料对剪切应力响应的指标。泊松比 (ν):横向应变与轴向应变之比。强度特性:定义材料的拉伸强度、压缩强度和剪切强度。热性能:如果分析涉及热效应,则需包含热膨胀系数和热导率等特性。.
剪切模量 (G):衡量材料对剪切应力响应的指标。泊松比 (ν):横向应变与轴向应变之比。强度特性:定义材料的拉伸强度、压缩强度和剪切强度。热性能:如果分析涉及热效应,则需包含热膨胀系数和热导率等特性。.
边界条件和载荷:
支撑和约束:定义复合结构的支撑方式。这可以包括固定支撑、简支边或自由边。.
荷载条件:明确结构将承受的荷载类型,例如拉力、压力、弯曲或剪切荷载。请注明这些荷载的大小和方向。.
网格划分:
单元类型:选择要使用的有限元类型(例如,薄结构使用壳单元,厚结构使用实体单元)。.
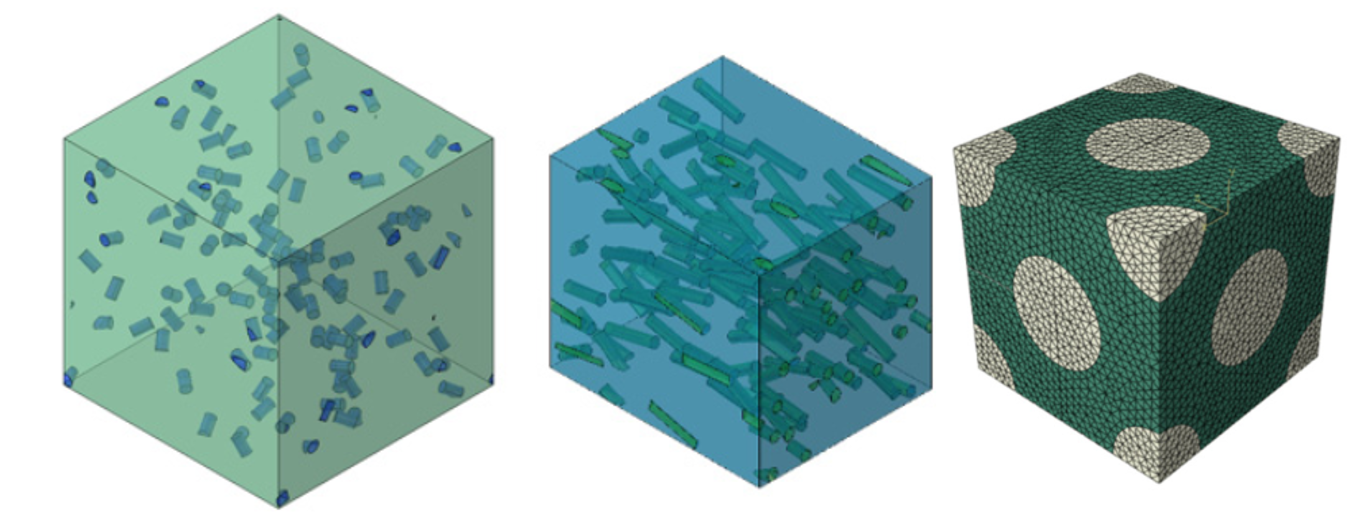
图 3:RVE 网格划分
Model Selection
为了利用人工智能进行损伤评估,建立损伤模型至关重要。该模型可以通过多种方法构建,例如: 哈辛损伤标准, 勒梅特模型,或者采用传统模型作为参考的伪颗粒失效模型。.
伪晶粒失效模型旨在通过考虑基体中短纤维的取向偏差来模拟复合材料的渐进失效。这对于短纤维热塑性塑料尤为适用。该模型将复合材料划分为伪晶粒,每个伪晶粒代表复合材料中具有特定纤维取向的小体积区域。它通过模拟这些伪晶粒在各种载荷条件下的损伤和失效来描述复合材料的非弹性行为。.
Data Collection for obtaining damage response in Artificial Neural Model damage
收集实验数据以验证模型。这包括测量杨氏模量、断裂韧性和其他力学性能。使用诸如 Digimat-MF 之类的仿真工具进行平均场均匀化处理,并预测复合材料的力学性能。这些工具有助于将模型预测结果与实验结果进行比较。.
Hidden layer in composite
对于使用神经网络对复合材料进行建模而言,隐藏层至关重要,它能够捕捉输入参数与所需输出属性之间的复杂关系。隐藏层是深度学习模型的计算核心,使神经网络能够逼近函数并从输入数据中捕捉模式。.
预训练和隐藏层:
在预训练阶段,神经网络(包括其隐藏层)会使用大型数据集(例如,均质化数据)进行训练。这有助于网络,尤其是隐藏层,学习数据中的一般特征和模式。隐藏层会捕获这些学习到的特征,这些特征构成了后续微调的基础。.
Hidden layers in a neural network are responsible for extracting features from the input data. During pre-training, these layers learn to identify and represent important patterns and structures in the data. Pre-training helps in initializing the weights of the hidden layers in a way that they are already tuned to capture general features. This makes the subsequent fine-tuning phase more effective and faster.
In a typical neural network training process, weights are often initialized randomly. This can sometimes lead to poor convergence or getting stuck in local minima. With weights initialized through pre-training, the network is already somewhat aligned with the underlying data distribution. This makes the fine-tuning phase more efficient, as the network requires fewer adjustments to reach optimal performance. By starting with pre-trained weights, the network is less likely to overfit the smaller, task-specific dataset during fine-tuning. This is because the initial weights already encode general knowledge, reducing the risk of the network becoming too specialized to the fine-tuning data.
在大数据集上进行预训练有助于隐藏层更好地泛化,这意味着它们可以捕获并非训练数据特有的特征,而是适用于更广泛的数据。.
– 这种泛化能力对于迁移学习过程至关重要,因为它允许预训练模型作为在更具体的数据集上进行微调的良好起点。.
利用有限元法或实验数据进行微调(微调阶段):
然后,使用从有限元模拟或实验数据中获得的更小、更精确的数据集对预训练模型进行微调。这一步骤提高了模型的准确性和性能。使用有限元模拟生成一个规模较小但保真度高的数据集。.
预训练模型是在大型数据集(平均场数据集)上训练的,并以此作为初始模型。微调则使用较小但高保真度的数据集(全场数据集)进行。微调过程包括使用高保真度数据调整预训练模型的所有可训练参数。与部分微调(冻结部分参数)相比,这种方法始终能获得更好的性能。.
这一详细过程突显了使用预训练模型并用高保真数据对其进行微调的重要性,从而在预测中实现更好的性能和准确性。.
- Performance Comparison (Evaluation in composite):
将迁移学习模型的性能与仅基于高保真数据集训练的模型进行比较。其中一种方法是平均相对误差 (MeRE) 和最大相对误差 (MaRE)。平均相对误差 (MeRE) 和最大相对误差 (MaRE) 是评估神经网络预测短纤维增强复合材料性能的关键指标。.
Understanding short fiber composites—and especially simulating their damage—can be tricky without the right guidance. That’s why we’ve created two tutorial packages!! Both packages aim to simulate damage in short fiber composites using Abaqus, they differ in their modeling approaches—macroscopic phenomenological modeling versus micromechanical homogenization—and the specific subroutines used for implementation.
两种短纤维复合材料损伤建模教程包的区别:
- 利用子程序模拟短纤维复合材料的损伤: 利用通过 VUSDFLD 子程序实现的宏观损伤模型(Dano 模型)。.
- 短纤维复合材料损伤(平均场均匀化模型): 采用通过 UMAT 子程序实现的平均场均匀化微机械方法。.
这 CAE 助手 我们致力于满足您所有的 CAE 需求,您的反馈对我们实现这一目标至关重要。如果您有任何疑问或遇到任何问题,请随时通过我们的社交媒体账号(包括 WhatsApp)与我们联系。.
结论
In the end Short Fiber Reinforced Composites (SFRCs) are favored for injection molding due to their enhanced properties compared to unfilled polymers. Two main micro-mechanical modeling approaches, mean-field and full-field models, are used to predict damage. Mean-field models, which average stress and strain within microstructural components, offer computational efficiency but lack detailed insights into deformation mechanisms and phase interactions, leading to lower accuracy than full-field models.
Full-field models, which simulate material behavior in detail, require significant computational resources for creating and analyzing Representative Volume Elements (RVE). Neural networks provide a superior alternative, achieving desired properties and full-field level accuracy without the trial-and-error process of generating an RVE. They use weights and biases to store learned knowledge, reducing memory and computational time, and can leverage transfer learning to enhance models with less data. Fine-tuned neural networks for short fiber composite model can predict unseen loading conditions with high accuracy.
Key elements in neural network modeling include hidden layers, activation functions, training, validation, normalization, and evaluation. Dense hidden layers approximate complex functions, while the ELU activation function introduces non-linearity to enhance pattern learning. Training involves iterative weight adjustments to minimize loss, and validation assesses the model’s generalization on unseen data to detect overfitting.
Normalization scales input data to a common range (typically [0, 1]) for efficient learning and faster convergence. Evaluation metrics like Mean Relative Error (MeRE) and Maximum Relative Error (MaRE) provide a thorough assessment of model performance. In composite modeling, crucial steps include material selection, volume fraction determination, geometry definition, and material property assignment. Boundary conditions and loading scenarios are defined, and meshing involves selecting appropriate finite elements.
The process includes pre-training the neural network on extensive datasets for general pattern learning and fine-tuning with high-fidelity data from FEM simulations or experiments, ensuring robust and accurate predictions.